Databricks Connector 1.0.0.1
The Databricks Connector lets you list, import, automate, and repair Databricks jobs.
What's New in 1.0.0.1
This version of the Databricks Connector introduces the following new Job Definitions.
-
Redwood_Databricks_RepairJob: Lets you repair a failed Databricks job.
-
Redwood_Databricks_StartCluster, Redwood_Databricks_StartCluster: Lets you start and stop a Databricks cluster.
Other improvements are as follows.
-
You can now run a Databricks job by its name, rather than only by its ID.
-
RunMyJobs now writes the status of all tasks within a Databricks Job to the Job log.
-
At the end of a job run, RunMyJobs generates an RTX file with a summary of all tasks.
-
The Redwood_Databricks_RunJob and Redwood_Databricks_RunJob_Template Job Definitions have a new Enable Restart Options parameter. If this is set to
Y, you can initiate the repair of a failed Databricks job in one click from a RunMyJobs Operator Message.
Prerequisites
- RunMyJobs 9.2.9 or later.
- Connection Management Extension 1.0.0.3 or later. Note that the Connection Management Extension will be installed or updated automatically if necessary when you install this Connector.
- Privileges Required to Use Connections
- Privileges Required to Use Databricks
Contents
| Object Type | Name | Description |
|---|---|---|
| Folder | GLOBAL.Redwood.REDWOOD.Databricks | Integration Connector with the Databricks system |
| Constraint Definition | REDWOOD.Redwood_DatabricksConnectionConstraint | Constraint for Databricks Connection fields |
| Constraint Definition | REDWOOD.Redwood_DatabricksNotRunningClusterConstraint | Constraint for Databricks Clusters fields |
| Constraint Definition | REDWOOD.Redwood_DatabricksNotTerminatedClusterConstraint | Constraint for Databricks Clusters fields |
| Extension Point | REDWOOD.Redwood_DatabricksConnection | Databricks Connector |
| Job Definition | REDWOOD.Redwood_Databricks_ImportJob | Import a job from Databricks |
| Job Definition | REDWOOD.Redwood_Databricks_RepairJob | Repair a failed Databricks job run |
| Job Definition | REDWOOD.Redwood_Databricks_RunJob | Run a job in Databricks |
| Job Definition | REDWOOD.Redwood_Databricks_RunJob_Template | Template Job Definition to run a job in Databricks |
| Job Definition | REDWOOD.Redwood_Databricks_ShowJobs | List all existing jobs in Databricks |
| Job Definition | REDWOOD.Redwood_Databricks_StartCluster | Start a cluster in Databricks |
| Job Definition | REDWOOD.Redwood_Databricks_StopCluster | Stop a cluster in Databricks |
| Job Definition Type | REDWOOD.Redwood_Databricks | Databricks Connector |
| Library | REDWOOD.Redwood_Databricks | Library for Databricks Connector |
Setup
- Locate the Databricks component in the Catalog and install it.
- Navigate to Configure > Extensions > Connections.
- Click New.
-
Click the Databricks connection type.
-
Click Next or Basic Properties, then create a Queue and Job Server for the Connector. All required settings will be set up automatically.
- Click Next or Security, then click
 to specify which roles can access the connection information. Redwood recommends granting the role at least the following additional privileges: View on the Databricks Connector Job Server, View Processes on the Databricks Connector Queue, View on library REDWOOD.Redwood_Databricks, and Run on any Job Definitions that users with this role will submit.
to specify which roles can access the connection information. Redwood recommends granting the role at least the following additional privileges: View on the Databricks Connector Job Server, View Processes on the Databricks Connector Queue, View on library REDWOOD.Redwood_Databricks, and Run on any Job Definitions that users with this role will submit. - Click Next or Databricks Connection Properties. You have two options for authenticating with Databricks.
Databricks Basic Authentication. Enter the URL for your Databricks instance, your Username, and your Password.
Databricks Personal Access Token. Enter the URL of your Databricks instance and your Access Token.
- Click Save & Close.
- Navigate to Configure > Control > Job Servers, locate your Databricks Connector Job Server, start it, and make sure it reaches status Running.
Job Definitions
Redwood_Databricks_ImportJob
Imports one or more Databricks jobs as RunMyJobs Job Definitions. Specify a Job Name Filter to control what jobs are imported, and Generation Settings to control the attributes of the imported definitions.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|---|
| Parameters | connection
|
Connection | The Connection object that defines the connection to the Databricks application. | String | In |
|
|
| Parameters | filter
|
Job Name Filter | This filter can be used to limit the amount of jobs returned to those which name matches the filter. Wildcards * and ? are allowed. |
String | In |
|
|
| Parameters | overwrite
|
Overwrite Existing Definition | When set to Yes, if a Definition already exists with the same name as the name generated for the imported object, it will be overwritten with the new import. When set to No, the import for that template will be skipped if a Definition with the same name already exists. | String | In | N
|
Y,N |
| Generation Settings | identifier
|
Job Identifier | Which field should be used as the Job Identifier on the imported Definitions. | String | In | JobName
|
JobName, JobID |
| Generation Settings | targetPartition
|
Partition | The Partition to create the new Definitions in. | String | In |
|
|
| Generation Settings | targetApplication
|
Folder | The Folder to create the new Definitions in. | String | In |
|
|
| Generation Settings | targetQueue
|
Default Queue | The default Queue to assign to the generated Definitions. | String | In |
|
|
| Generation Settings | targetPrefix
|
Definition Name Prefix | The prefix to add onto the name of the imported Databricks Job to create the Definition name. | String | In | CUS_DBCKS_
|
|
Redwood_Databricks_RepairJob
Repairs a failed Databricks job run.
Parameters
| Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|
connection
|
Connection | The Connection object that defines the connection to the Databricks application. | String | In |
|
|
jobRunId
|
Job Run Id | The unique id of the Job Run to perform the repair against. | String | In |
|
|
lastRepairId
|
Last Repair Id | The repair id for the last repair run if this job run has previously been repaired. | String | In |
|
|
enableRestartOptions
|
Enable Restart Options | Set this to Y, to enable restart options for Databricks job. If the Databricks Job fails, the RunMyJobs Job will go to status Console and await the reply from a generated Operator Message before proceeding. |
String | In | N
|
Y, N |
sparkJarParameters
|
Spark Jar Parameters | An array of Spark Jar parameters to be used on the Databricks Job. | String | In |
|
|
sparkSubmitParameters
|
Spark Submit Parameters | An array of Spark Submit parameters to be used on the Databricks Job. | String | In |
|
|
notebookParameters
|
Notebook Parameters | An array key=value pairs of Notebook parameters to be used on the Databricks Job. | String | In |
|
|
pythonParameters
|
Python Parameters | An array of Python parameters to be used on the Databricks Job. | String | In |
|
|
pythonNamedParameters
|
Python Named Parameters | An array key=value pairs of Python named parameters to be used on the Databricks Job. | String | In |
|
|
sqlParameters
|
SQL Parameters | An array key=value pairs of SQL parameters to be used on the Databricks job. | String | In |
|
|
dbtParameters
|
DBT Parameters | An array of DBT parameters to be used on the Databricks job. | String | In |
|
|
pipelineFullRefresh
|
Pipeline Full Refresh | Should a full refresh be performed on the Databricks Pipeline job. | String | In |
|
Y, N |
runId
|
Databricks Run Id | The Job Run ID of the Databricks job. | String | Out |
|
|
repairId
|
Databricks Repair Id | The Repair ID for this repair run. | String | Out |
|
|
taskSummary
|
Task Summary | Summary of all tasks that were part of this run. | Table | Out |
|
|
Redwood_Databricks_RunJob
Runs a Databricks job and monitors it until completion. The RunMyJobs Job will remain in a Running state until the Databricks job completes. If the Databricks job succeeds, the RunMyJobs Job will complete successfully. If the Databricks job fails, the RunMyJobs Job will complete in Error, and any available error information will be written to the stdout.log file.
Parameters are available on the definition to pass In Parameters for the different types of Databricks tasks. For example, adding a value to the Python parameters parameter will make that parameter available to all Python tasks in the Databricks job. If the job does not require parameters for a certain task type, leave that parameter empty. See the Parameters table below for more information.
Parameters
| Name | Description | Documentation | Data Type | Direction | Values |
|---|---|---|---|---|---|
connection
|
Connection | The Connection object that defines the connection to the Databricks application. | String | In |
|
jobId
|
Job ID to run | The job ID in Databricks to execute. | String | In |
|
jobName
|
Job Name | The name of the job to run. This can be provided instead of the job ID. | String | In | |
enableRestartOptions
|
Enable Restart Options | Set this to Y, to enable restart options for Databricks job. If the Databricks job fails, the RunMyJobs Job will go to status Console and await the reply from a generated Operator Message before proceeding. |
String | In | N
|
sparkJarParameters
|
Spark Jar Parameters | An array of Spark Jar parameters to be used on the Databricks job. | String | In | |
sparkSubmitParameters
|
Spark Submit Parameters | An array of Spark Submit parameters to be used on the Databricks job. | String | In |
|
notebookParameters
|
Notebook Parameters | An array key=value pairs of Notebook parameters to be used on the Databricks job. | String | In |
|
pythonParameters
|
Python Parameters | An array of Python parameters to be used on the Databricks job. | String | In |
|
pythonNamedParameters
|
Python Named Parameters | An array key=value pairs of Python named parameters to be used on the Databricks job. | String | In |
|
sqlParameters
|
SQL Parameters | An array key=value pairs of SQL parameters to be used on the Databricks job. | String | In |
|
dbtParameters
|
DBT Parameters | An array of DBT parameters to be used on the Databricks job. | String | In |
|
pipelineFullRefresh
|
Pipeline Full Refresh | Should a full refresh be performed on the Databricks Pipeline job. | String | In | Y=Yes, N=No |
runId
|
Databricks Run ID | The Run ID of the executed job on the Databricks side. | String | Out |
|
taskSummary
|
Task Summary | Summary of all tasks that were part of this run. | Table | Out |
Redwood_Databricks_RunJob_Template
This template definition is provided to facilitate creating Job Definitions that run specific Databricks jobs. Its functionality and Parameters are the same as the Redwood_Databricks_RunJob Job Definition. To create a Job Definition, Choose New (from template) from the context menu of Redwood_Databricks_RunJob_Template.
Note: To provide a default value for the Connection in the Connection parameter of the template, you must use the full Business Key of the Connection: EXTConnection:<Partition>.<ConnectionName>. Example: EXTConnection:GLOBAL.MyDatabricksConnection
Redwood_Databricks_ShowJobs
Fetches information about the available Databricks jobs. Job properties for returned jobs are written to the stdout.log file, the file named listing.rtx, and the Out Parameter Job Listing.
Parameters
| Name | Description | Documentation | Data Type | Direction |
|---|---|---|---|---|
connection
|
Connection | The Connection object that defines the connection to the Databricks application. | String | In |
filter
|
Job Name Filter | This filter can be used to limit the amount of jobs returned to those which name matches the filter. Wildcards * and ? are allowed. |
String | In |
listing
|
Job listing | The listing of all jobs available that match the input filter (or any if no input filter was provided). | Table | Out |
Redwood_Databricks_StartCluster
Starts a cluster in Databricks.
Parameters
| Name | Description | Documentation | Data Type | Direction |
|---|---|---|---|---|
connection
|
Connection | The Connection object that defines the connection to the Databricks application. | String | In |
clusterId
|
Cluster to start | This is the cluster id in Databricks to start. | String | In |
Redwood_Databricks_StopCluster
Stops a cluster in Databricks.
Parameters
| Name | Description | Documentation | Data Type | Direction |
|---|---|---|---|---|
connection
|
Connection | The Connection object that defines the connection to the Databricks application. | String | In |
clusterId
|
Cluster to stop | This is the cluster id in Databricks to stop. | String | In |
Procedures
Listing Databricks Jobs
To retrieve a list of Databricks jobs:
- Navigate to Configure > Automate > Job Definitions and run Redwood_Databricks_ShowJobs.
-
Choose the Connection.
-
Choose a Namespace.
-
To specify a search string for the job name, enter a value in the Job Name Filter field. Wildcards * and ? are supported.
-
Submit the Job Definition.
Importing a Databricks Job
To import a Databricks job:
-
Run Redwood_Databricks_ImportJob.
-
On the Parameters tab, do this:
-
Choose the Connection.
-
To specify a search string for the job name, enter a value in the Job Name Filter field. Regular expressions are supported.
-
Choose an option from the Overwrite Existing Definition dropdown list.
-
-
On the Generation Settings tab, do this:
-
Choose an option from the Job Identifier dropdown list.
-
Optionally specify a Partition, Folder, and/or Default Queue.
-
In the Definition Name Prefix field, enter a prefix to add onto the name of the imported Databricks job when creating the name of the Job Definition.
-
-
Click Run.
Running a Databricks Job
To run a Databricks job:
-
Run Redwood_Databricks_RunJob.
-
In the Parameters tab, specify the parameters you want to use for the job. For more information, see Redwood_Databricks_RunJob.
-
Click Run.
Running a Databricks Job with a Template
To create a customized Job Definition, optionally with default values, for a Databricks job:
-
Right-click the Redwood_Databricks_RunJob_Template Job Definition and choose New (from Template) from the context menu. The New Job Definition pop-up window displays.
-
Choose a Partition.
-
Enter a Name.
- Delete the default Folder value (if any) and substitute your own Folder name if desired.
-
In the Parameters tab, enter any Default Expressions you want to use.
-
When specifying the Connection value, use the format
EXTCONNECTION:<partition>.<connection name>.
-
-
Save and then run the new Job Definition.
Repairing a Databricks Job
If a step in a Databricks job fails (for example, because of bad parameter or a temporary network connectivity issue), you can click Repair run for that job in the Databricks user interface, and the job will resume running starting with the step that failed, rather than starting over from scratch. Being able to do this from RunMyJobs makes it easier to address issues that (for example) cause a Workflow to fail in the middle of execution without having to use the Databricks user interface.
There are two ways to repair a failed Databricks job in RunMyJobs.
-
When you submit the Redwood_Databricks_RunJob Job Definition, set the Enable Restart Options parameter to
Y. If the Databricks job fails, RunMyJobs will generate an Operator Message. Once the issue has been resolved, the Operator can choose Repair Databricks Job from the Reply dropdown list in the Operator Reply dialog box to repair the job immediately.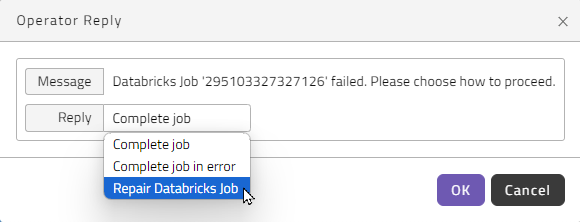
-
Run the Redwood_Databricks_RepairJob Job Definition. This approach allows you to change the job's parameters if necessary.
Note: It is possible that a call to the Redwood_Databricks_RepairJob Job Definition may itself fail. If you manually rerun the Redwood_Databricks_RepairJob Job Definition to repair the job again, make sure you enter the Repair ID from the failed repair run (you can find this in the repairId Out Parameter) as the Last Repair Id In Parameter. That way, Databricks knows where to pick up repairing the job again. (If you use the Repair Databricks Job option in the Operator Reply dialog box, rather than manually resubmitting the Job Definition, the Repair ID is sent to Databricks automatically.)
Starting a Databricks Cluster
To start a Databricks cluster:
-
Right-click the Redwood_Databricks_StartCluster Job Definition and choose Run from the context menu.
-
Choose the Connection.
-
Select the name of the cluster to restart from the Cluster to start dropdown list.
-
Click Run.
Stopping a Databricks Cluster
To stop a Databricks cluster:
-
Right-click the Redwood_Databricks_StopCluster Job Definition and choose Run from the context menu.
-
Choose the Connection.
-
Select the name of the cluster to restart from the Cluster to stop dropdown list.
-
Click Run.