Kubernetes Connector 1.0.0.0
The Kubernetes Connector lets you find, run, import, and delete Kubernetes jobs.
Note: Kubernetes jobs are defined in YAML format.
Note: Kubernetes job names must be unique. To avoid name collisions, use the YAML generateName attribute.
Prerequisites
- RunMyJobs 9.2.9 or higher.
- Connection Management Extension 1.0.0.4 or later. This Extension will be installed or updated automatically if necessary when you install the Kubernetes Connector.
- Privileges Required to Use the Kubernetes Connector.
- A Kubernetes API Server that can be reached via outbound HTTP from the Secure Gateway (for SaaS customers) or the RunMyJobs Scheduler (for on-site installations).
- Token or Client Certificate authorization must be configured on the Kubernetes API Server.
Contents
| Object Type | Name | Description |
|---|---|---|
| Folder | GLOBAL.Redwood.REDWOOD.Kubernetes | Integration Connector with a Kubernetes cluster |
| Constraint Definition | REDWOOD.Redwood_KubernetesConnectionConstraint | Constraint for Kubernetes Connection fields |
| Constraint Definition | REDWOOD.Redwood_KubernetesNamespaceConstraint | Constraint for Kubernetes Namespaces fields |
| Extension Point | REDWOOD.Redwood_KubernetesConnection | Kubernetes Connection |
| Job Definition | REDWOOD.Redwood_Kubernetes_DeleteJobs | Delete one or more Kubernetes Jobs |
| Job Definition | REDWOOD.Redwood_Kubernetes_ImportJob | Import a job from Kubernetes |
| Job Definition | REDWOOD.Redwood_Kubernetes_RunExistingJob | Run an existing job in Kubernetes |
| Job Definition | REDWOOD.Redwood_Kubernetes_RunExistingJob_Template | Template Job Definition to run an existing job in Kubernetes |
| Job Definition | REDWOOD.Redwood_Kubernetes_RunJob | Run a job in Kubernetes |
| Job Definition | REDWOOD.Redwood_Kubernetes_RunJob_Template | Template Job Definition to run a job in Kubernetes |
| Job Definition | REDWOOD.Redwood_Kubernetes_ShowJobs | List all existing jobs in a Kubernetes cluster |
| Job Definition Type | REDWOOD.Redwood_Kubernetes | Kubernetes Connector |
| Library | REDWOOD.Redwood_Kubernetes | Library for Kubernetes Connector |
Setup
- Locate the Kubernetes component in the Catalog and install it.
- Navigate to Configure > Admin > Security > Connections.
- Click New.
-
Click the Kubernetes connection type.
-
Click Next or Basic Properties, then create a Queue and Job Server for the Connector. All required settings will be configured automatically.
- Click Next or Security, then click
 to specify which roles can access the Connection information. It is recommended to grant the role at least the following additional privileges: View on the Kubernetes Connector Job Server, View Processes on the Kubernetes Connector Queue, View on library REDWOOD.Redwood_EnterpriseOne, and Run on any Job Definitions that users with this role will run.
to specify which roles can access the Connection information. It is recommended to grant the role at least the following additional privileges: View on the Kubernetes Connector Job Server, View Processes on the Kubernetes Connector Queue, View on library REDWOOD.Redwood_EnterpriseOne, and Run on any Job Definitions that users with this role will run. - Click Next or Kubernetes Connection Properties. You have two options for authenticating with Kubernetes.
Kubernetes Certificate. Enter the URL for your Kubernetes instance. Use the Test Connection button to make sure the connection is working.
Note: If you choose this option, you will need to create an X509_TrustedCertificate Credential.
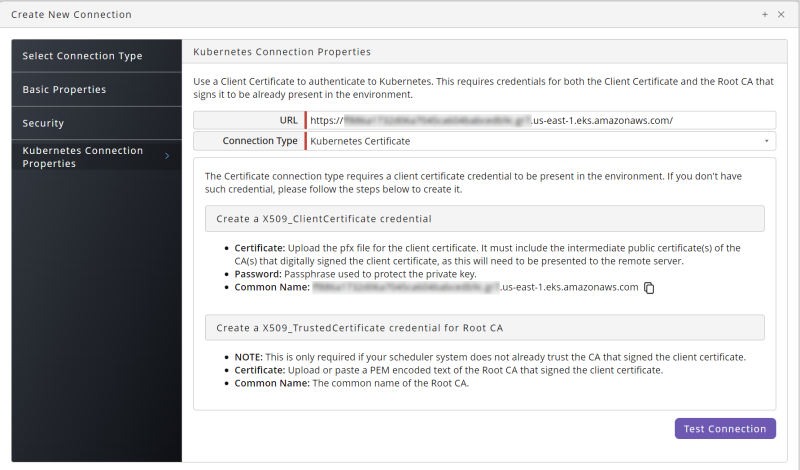
Kubernetes Token Authentication. If you choose this option, enter the URL and Access Token for your Kubernetes API Server.
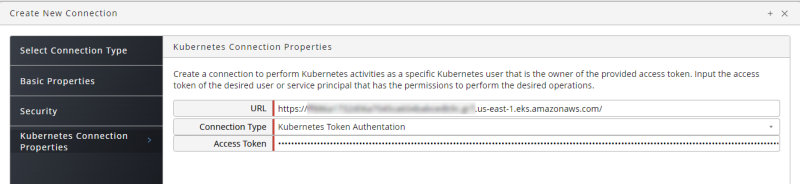
- Click Save & Close.
- Navigate to Configure > Control > Job Server, locate your Kubernetes Connector Job Server, start it, and make sure it reaches status Running.
Job Definitions
Redwood_Kubernetes_DeleteJobs
Deletes one or more Kubernetes jobs.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|---|
| Parameters | connection
|
Connection | The Connection object that defines the connection to the Kubernetes cluster. | String | In |
|
|
| Parameters | namespace
|
Namespace | The Namespace at the Kubernetes cluster. | String | In |
|
|
| Parameters | nameFilter
|
Job Name Filter | Name filter to specify the jobs to delete. Provide an exact name, or wildcards * and ? are supported. | String | In |
|
|
| Parameters | olderThan
|
Older Than (Days) | Only delete jobs that are older than (by completion date/time) the specified number of days. | Number | In | 10
|
|
| Parameters | propagationPolicy
|
Propagation Policy | How to handle dependent objects. Orphan: Orphan the dependents. Background: The garbage collector will delete the dependents in the background. Foreground: Delete all dependents in the foreground. | String | In | Background | Background, Foreground, Orphan |
Redwood_Kubernetes_ImportJob
Imports one or more jobs from Kubernetes.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|---|
| Parameters | connection
|
Connection | The Connection object that defines the connection to the Kubernetes cluster. | String | In |
|
|
| Parameters | namespace
|
Namespace | The Namespace at the Kubernetes cluster. | String | In |
|
|
| Parameters | filter
|
Job Name Filter | This filter can be used to limit the amount of jobs returned to those which name matches the filter. Valid regular expressions are supported in this field. | String | In |
|
|
| Parameters | overwrite
|
Overwrite Existing Definition | When set to Yes, if a Job Definition already exists with the same name as the name generated for the imported object, it will be overwritten with the new import. If set to No, the import for that template will be skipped if a Job Definition with the same name already exists. | String | In | N
|
Y, N |
| Generation Settings | targetPartition
|
Partition | The Partition to create the new Job Definitions in. | String | In |
|
QueryFilter:User.Redwood System.Partition.Partition%2e;all |
| Generation Settings | targetApplication
|
Folder | The Folder to create the new Job Definitions in. | String | In |
|
QueryFilter:User.Redwood System.Application.Application%2e;all |
| Generation Settings | targetQueue
|
Default Queue | The default Queue to assign to the generated Job Definitions. | String | In |
|
QueryFilter:User.Redwood System.Queue.Queue%2e;all |
| Generation Settings | targetPrefix
|
Definition Name Prefix | The prefix to add onto the name of the imported Kubernetes job to create the Job Definition name. | String | In | CUS_K8S_
|
|
Redwood_Kubernetes_RunExistingJob
Runs an existing job in Kubernetes.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|---|
| Parameters | connection
|
Connection | The Connection object that defines the connection to the Kubernetes cluster. | String | In |
|
|
| Parameters | namespace
|
Namespace | Namespace to run the job in. | String | In |
|
|
| Parameters | name
|
Job name to run | The name of the Kubernetes job to re-run. This job must already exist on the server. | String | In |
|
|
| Parameters | downloadLogs
|
Download Logs | Download log files from the containers that ran as part of this job and attach them as Job files. | String | In | No | No, Failed Pods Only, All |
| Parameters | controllerUid
|
Kubernetes Controller UID | The Controller UID of the executed Job on the Kubernetes side | String | Out |
|
|
Redwood_Kubernetes_RunExistingJob_Template
Template Job Definition to run an existing job in Kubernetes.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|---|
| Parameters | connection
|
Connection | The Connection object that defines the connection to the Kubernetes cluster. | String | In |
|
|
| Parameters | namespace
|
Namespace | Namespace to run the job in | String | In |
|
|
| Parameters | name
|
Job name to run | The name of the Kubernetes job to re-run. This job must already exist on the server. | String | In |
|
|
| Parameters | downloadLogs
|
Download Logs | Download log files from the containers that ran as part of this job and attach them as Job files. | String | In | No | No, Failed Pods Only, All |
| Parameters | controllerUid
|
Kubernetes Controller UID | The Controller UID of the executed job on the Kubernetes side | String | Out |
|
|
Redwood_Kubernetes_RunJob
Runs a job in Kubernetes.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|---|
| Parameters | connection
|
Connection | The Connection object that defines the connection to the Kubernetes cluster. | String | In |
|
|
| Parameters | namespace
|
Namespace | Namespace to run the job in | String | In |
|
|
| Parameters | yamlFile
|
YAML File | The YAML file defining the job properties | File | In |
|
|
| Parameters | downloadLogs
|
Download Logs | Download log files from the containers that ran as part of this job and attach them as Job files. | String | In | No | No, Failed Pods Only, All |
| Parameters | jobName
|
Kubernetes Job Name | The Name of the executed job on the Kubernetes side | String | Out |
|
|
| Parameters | controllerUid
|
Kubernetes Controller UID | The Controller UID of the executed job on the Kubernetes side | String | Out |
|
|
Redwood_Kubernetes_RunJob_Template
Template Job Definition to run a job in Kubernetes.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|---|
| Parameters | connection
|
Connection | The Connection object that defines the connection to the Kubernetes cluster. | String | In |
|
|
| Parameters | namespace
|
Namespace | Namespace to run the job in | String | In |
|
|
| Parameters | downloadLogs
|
Download Logs | Download log files from the containers that ran as part of this job and attach them as Job files. | String | In | No | No, Failed Pods Only, All |
| Parameters | jobName
|
Kubernetes Job Name | The Name of the executed job on the Kubernetes side | String | Out |
|
|
| Parameters | controllerUid
|
Kubernetes Controller UID | The Controller UID of the executed job on the Kubernetes side | String | Out |
|
|
Redwood_Kubernetes_ShowJobs
Lists all existing jobs in a Kubernetes cluster.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction |
|---|---|---|---|---|---|
| Parameters | connection
|
Connection | The Connection object that defines the connection to the Kubernetes cluster. | String | In |
| Parameters | filter
|
Job Name Filter | This filter can be used to limit the number of jobs returned to those which name matches the filter. Wildcards * and ? are supported | String | In |
| Parameters | namespace
|
Namespace | The Namespace at the Kubernetes cluster. | String | In |
| Parameters | listing
|
Job listing | The listing of all jobs available that match the input filter (or any if no input filter was provided) | Table | Out |
Procedures
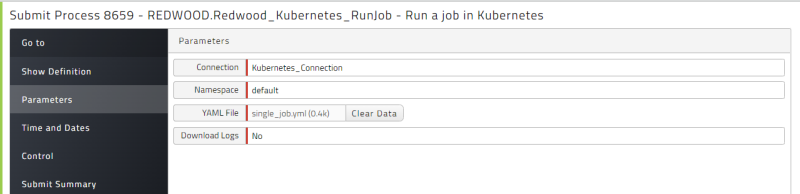
Running a Kubernetes Job from a YAML File
To run a Kubernetes job from a YAML file:
-
From the Kubernetes Folder, run Redwood_Kubernetes_RunJob.
-
Choose the Connection.
-
Choose a Namespace.
-
Upload the YAML File that defines the job you want to run.
-
Choose an option from the Download Logs dropdown list.
-
Click Run.
Finding Existing Kubernetes Jobs
To retrieve the list of existing Kubernetes jobs (that is, Kubernetes jobs that have already been submitted at least once):
-
From the Kubernetes Folder, run Redwood_Kubernetes_ShowJobs.
-
Choose the Connection.
-
To specify a search string, enter a value in the Job Name Filter field. Wildcards * and ? are supported.
-
Choose a Namespace.
-
Once the Job has finished, right-click the Job Definition and choose Monitor Related Processes, then select the Job and click
listing.rtxin the Detail View. Sample output is shown below.
Running an Existing Kubernetes Job
To run a Kubernetes job that has already run:
-
From the Kubernetes Folder, run Redwood_Kubernetes_RunExistingJob.
-
Choose the Connection.
-
Choose a Namespace.
-
Enter the name of the job you want to run.
-
Choose an option from the Download Logs dropdown list.
-
Click Run.
Running a Kubernetes Job with a Template
To create a customized Job Definition, optionally with default values, for a Kubernetes job defined in a YAML file:
-
Right-click the Redwood_Kubernetes_RunExistingJob_Template Job Definition and choose New (from Template) from the context menu. The New Job Definition screen displays.
-
Choose a Partition.
-
Enter a Name.
- Delete the default Folder value (if any) and substitute your own Folder name if desired.
-
Paste the YAML that defines the job you want to run in the Source field.
Note: If you want to use custom parameters in your YAML script, insert them using the format
${parameterName}.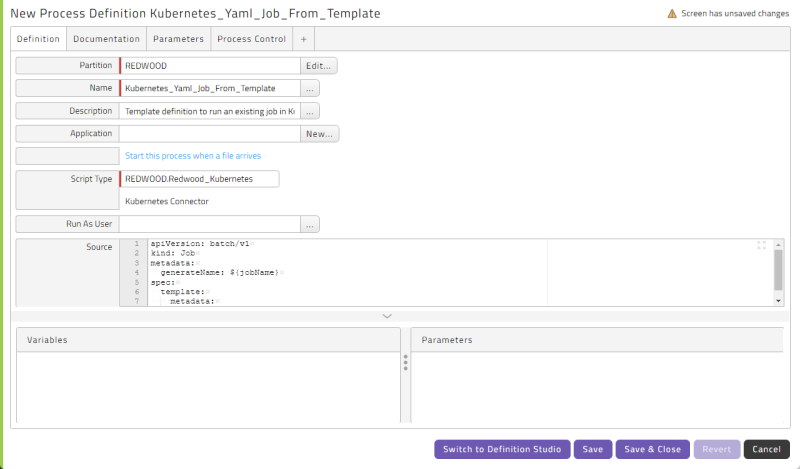
-
In the Parameters tab, enter any Default Expressions you want to use.
-
When specifying the Connection value, use the format
EXTCONNECTION:<partition>.<connection name>.
-
-
If you included parameters in your YAML, create an additional Parameter in the Parameters tab for each of them. For example, if you used
${jobName}in the YAML, create a Parameter namedjobName(and optionally specify a Default Expression). Supported Parameter types are String and Number.Note: If you use a parameter in the YAML, but you do not create a corresponding Parameter in the Parameters tab, the parameter reference will be submitted as-is (for example, as "${jobName}"). If you use a parameter in the YAML, but do not specify a value for it, it will be submitted as an empty string.
There are no specific requirements for Parameter Groups.
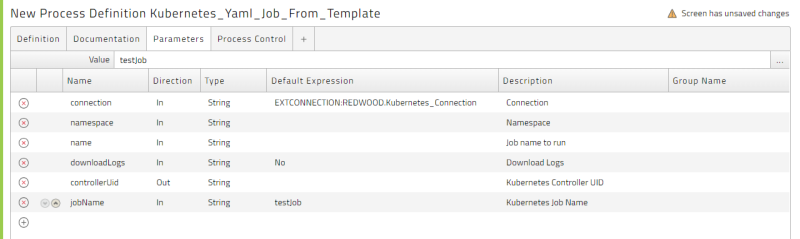
-
Save and then run the new Job Definition.
Running an Existing Kubernetes Job with a Template
To create a customized Job Definition, optionally with default values, for an existing Kubernetes job:
-
Right-click the Redwood_Kubernetes_RunExistingJob_Template Job Definition and choose New (from Template) from the context menu. The New Job Definition screen displays.
-
Choose a Partition.
-
Enter a Name.
- Delete the default Folder value (if any) and substitute your own Folder name if desired.
-
In the Parameters tab, enter any Default Expressions you want to use.
-
When specifying the Connection value, use the format
EXTCONNECTION:<partition>.<connection name>.
-
-
Save and then run the new Job Definition.
Importing a Kubernetes Job
To import an existing Kubernetes job (that is, a Kubernetes job that has already been submitted at least once):
-
From the Kubernetes Folder, run Redwood_Kubernetes_ImportJob.
-
On the Parameters tab:
-
Choose the Connection.
-
Choose a Namespace.
-
To specify a search string for the job name, enter a value in the Job Name Filter field. Regular expressions are supported.
-
Choose an option from the Overwrite Existing Definition dropdown list.
-
-
On the Generation Settings tab:
-
Optionally specify a Partition, Folder, and/or Default Queue.
-
In the Definition Name Prefix field, enter a prefix to add onto the name of the imported Kubernetes job when creating the name of the Job Definition.
-
-
Click Run.
Deleting Kubernetes Jobs
To delete existing Kubernetes jobs (that is, Kubernetes jobs that have already been submitted at least once) from the Kubernetes instance:
-
From the Kubernetes Folder, run Redwood_Kubernetes_DeleteJobs.
-
On the Parameters tab:
-
Choose the Connection.
-
Choose a Namespace.
-
To specify a search string for the job name, enter a value in the Job Name Filter field. Wildcards * and ? are supported.
-
To delete only jobs that are older than a given number of days, enter that number in the Older Than (Days) field.
-
To specify how to handle dependent objects for the job(s), choose an option from the Propagation Policy dropdown list.
-
Orphan: Orphan the dependents.
-
Background: The garbage collector will delete the dependents in the background.
-
Foreground: Delete all dependents in the foreground.
-
-
-
Click Run.
Determining Final Job Status
RunMyJobs monitors the status of a Kubernetes job by watching the job's active count. If the active count is not updated for some reason, RunMyJobs fetches the status of each pod and uses it to determine whether any pods are still active.
Once a Kubernetes job has completed, RunMyJobs determines the final status of the Job that ran it based on the following criteria.
-
If the Kubernetes job’s status conditions are present and the
Succeededcondition is true, the Job goes into Completed status. Otherwise the Job goes into Error status. -
If the Kubernetes job's status conditions are not present, RunMyJobs considers the final status of its pods. If any pods have
FailedorUnknownstatus, the RunMyJobs Job goes into Error status. If all pods reachSucceededstatus, the RunMyJobs Job goes into Completed status.